Dewdrop version 0.2 | Quick Start Guide
You can view the full documentation for Dewdrop here
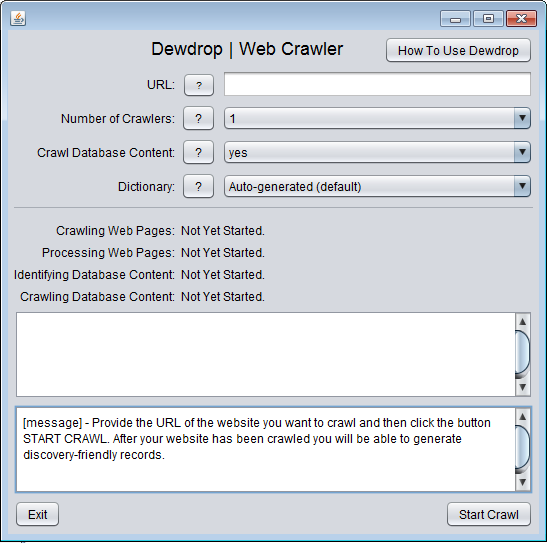
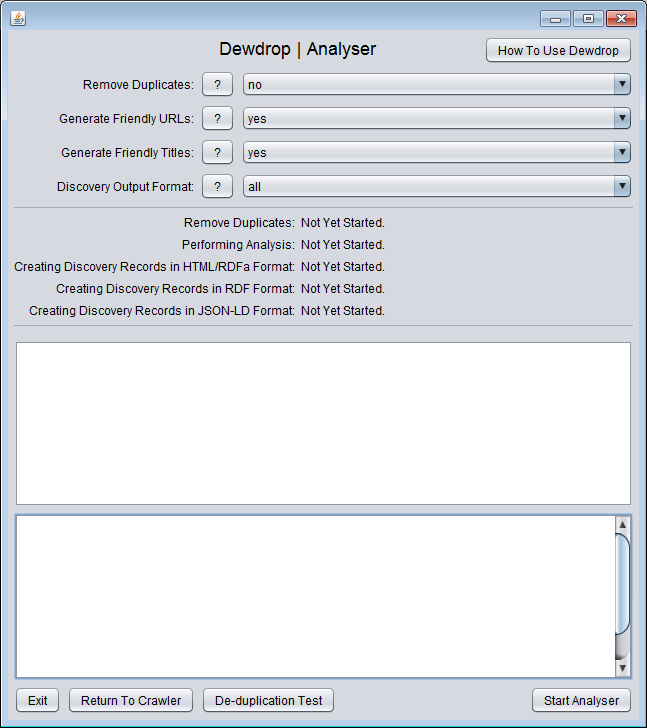
- There are only two screens for the user interface. You can see what the screens look like here: Screen#1: Crawler and here: Screen #2: Analyser
- First, you need to crawl a website:
- Launch the program "Dewdrop.exe" if you are using a Windows computer. Launch the program "Dewdrop.jar" if you are using a Linux or Apple computer.
- In the box
URL provide a valid URL for the website you wish to crawl, such as "http://www.hrionline.ac.uk/dewdrop-test".
- The URL must identify a domain or a directory within the domain. It must not identify a specific web page. Web pages and any query string values must be removed from the URL by the user. For example, the following URL is correct: "http://www.hrionline.ac.uk/dewdrop-test" whereas the URL "http://www.hrionline.ac.uk/dewdrop-test" is incorrect.
- Keep the option
Number of Crawlers as "1".
- Keep the option
Dictionary as "default".
- Keep the option
Crawl Database Content as "yes".
- Websites with large databases will have a significant impact on the duration of the crawl. As such, the user could consider using only the top 100 most frequent keywords found on the website's standard HTML pages. The option is available in the dropdown menu for
Crawl Database Content.
- Click the button
Start Crawl.
- Dewdrop will proceed to crawl the website. The first message panel provides information about the crawler's progress. The second message panel provides instructions to the user.
- Wait for the crawler to finish. On large sites crawling can take a very long time. When it has finished you will see an instruction in the second message panel which includes information about how many pages it has found.
- Next, you need to analyse the crawled content and create discovery-friendly records:
- Click the button
Next. This takes you to the Analyser screen.
- Keep the option
Remove Duplicates as "no".
- Keep the option
Generate Friendly URLs as "yes".
- Keep the option
Generate Friendly Titles as "yes".
- Change the option
Discovery Output Format to "HTML with RDFa".
- Click the button
Start Analyser.
- Dewdrop will proceed to analyse the crawled content. When it is finished Dewdrop will create the discovery-friendly records in your chosen output format. Wait for the process to finish.
- When Dewdrop is finished the message panel will explain that you can now access your discovery-friendly records.
- There are two ways in which you can access your discovery-friendly records:
- First, by clicking the
View Discovery Records button which provides a basic HTML interface for viewing the records.
- Second, by navigating to Dewdrop's home directory. You will see that Dewdrop has created a directory called "logs". This contains a further directory called "discovery". Your discovery-friendly URLs are located in the directory called "discovery".
- Finally, you might wish to deploy the discovery-friendly records on your website:
- We recommend that the following steps are undertaken by your server administrator.
- First, check with your server administrator to ensure that the steps outlined below are permitted by your server environment. In some instances the server administrator might need to undertake some additional configuration of the server.
- The "discovery" directory should contain a directory which is the name of the discovery output format. For example: "rdfa" if you chose the output format "HTML with RDFa".
- Copy the "rdfa" directory to the root directory of your website.
- The "rdfa" directory will contain your discovery records, plus some additional files called "sitemap.xml", ".htaccess" and "htmapper.txt".
- Move these additional files to the root directory of your website. Also, if present, move any file that includes the word "sitemap" in its filename, such as "sitemap_index.xml" and "sitemap1.xml".
- For example, if your website has the root directory "mywebsite" which contains the file "index.htm" and a directory of web pages called "pages", the discovery-friendly records should be deployed to the root of the directory like so:
/mywebsite
index.htm
/pages
sitemap.xml
/rdfa
.htaccess
htmapper.txt
In this example, the discovery-friendly records that are deployed consist of a file called "sitemap.xml", a directory called "rdfa", a file called ".htaccess" and a file called "htmapper.txt".
- Alternatively, you might wish to provide a third party content aggregator with access to your discovery-friendly records:
- The "discovery" directory should contain a directory which is the name of the discovery output format. For example: "rdfa" if you chose the output format "HTML with RDFa".
- The "rdfa" directory will contain your discovery records, plus some additional files called "sitemap.xml", ".htaccess" and "htmapper.txt".
- Simply provide the third party with a copy of this directory.
You can view the full documentation for Dewdrop here
{kind=link}
{kind=link}