Session 16Saturday 10:00 - 11:30High Tor 2Chair: George Ionita |
|---|
What do we write about in the Digital Humanities? A comparative study of Chinese and English publications
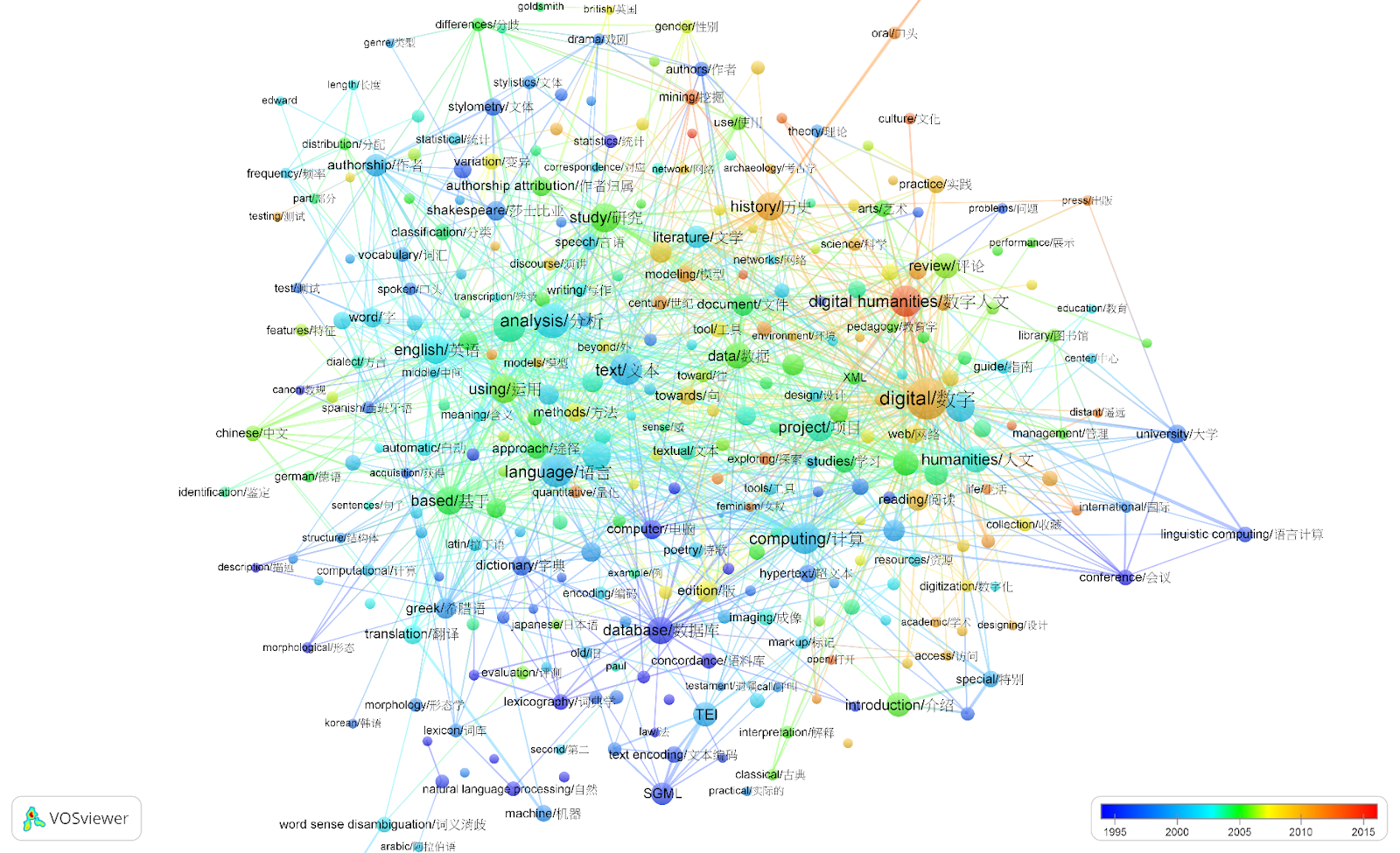
University College LondonMuch progress has been made recently in understanding and developing Digital Humanities (DH) as an increasingly global wissensraum or ‘knowledge space’ that transcends geographical boundaries. Yet, much of the substantial DH research that has been ongoing in mainland China since the 1990s is unknown in this knowledge space. This is evidenced by the website of the Association of Digital Humanities Organisations (ADHO) which records no link with China and the centerNet map, where the mainland China area lies empty. This paper seeks to highlight this disconnect, reveal the contours of the rapidly growing DH community in mainland China through an analysis of Chinese- and English-language academic publication titles. What commonalities and divergencies can be detected in the literature of the Chinese- and English-speaking communities from a comparative study of the titles of their articles? This paper constructs English and Chinese title word co-occurrence networks based on 3,247 English-language DH articles (from Chum, LLC/DSH, DHQ 1966-2017) and 1,698 Chinese-language DH articles (from Google Scholar 1964-2018). It calculates the frequency matrix of each two words appearing in the same title (co-occurrence), translates the title words into English and Chinese, visualises the bilingual networks with average year, and explores the intellectual structures and histories of the two networks. Figure 1: English title word co-occurrence network
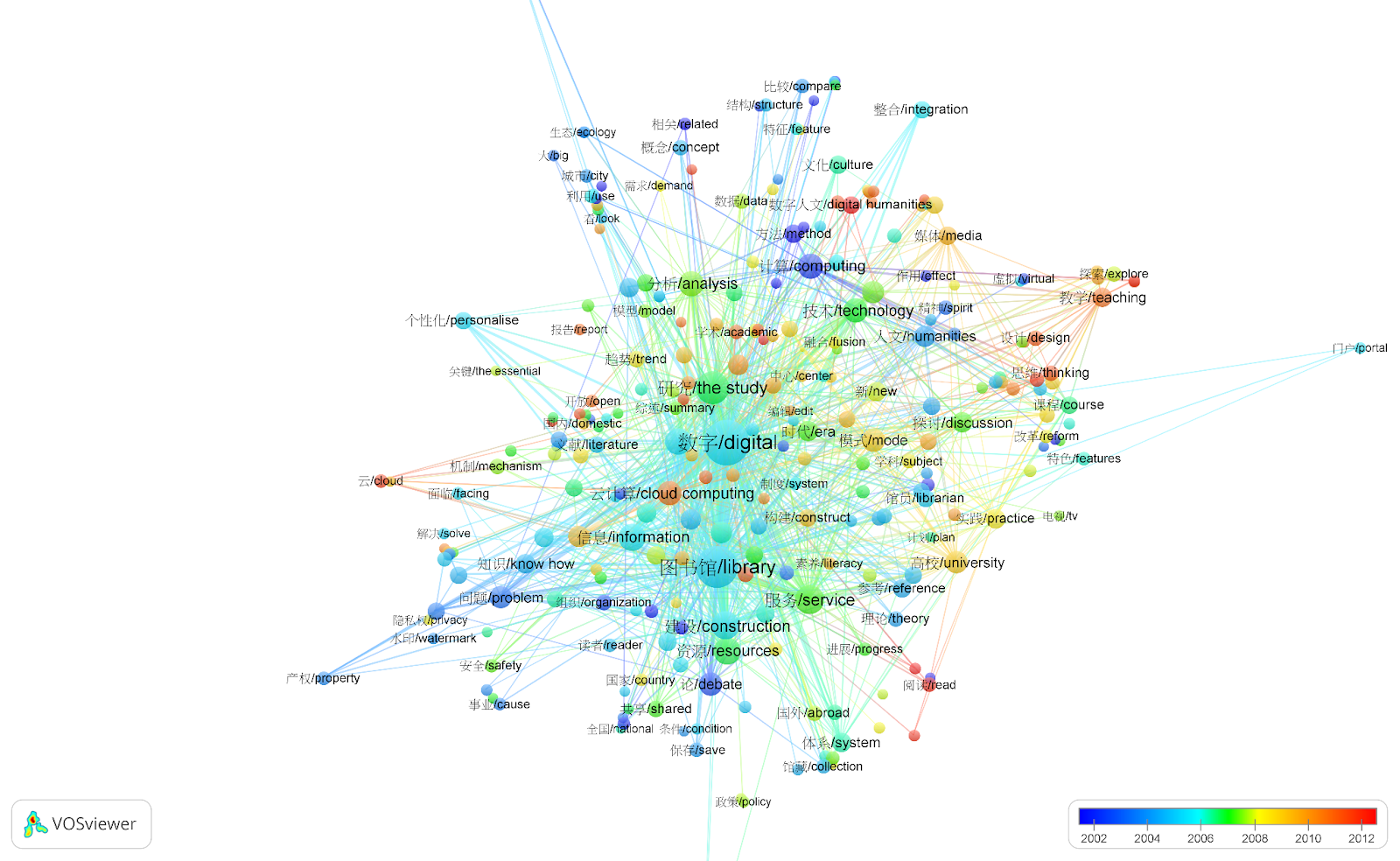
Figure 2: Chinese title word co-occurrence network
Results indicate that English-language articles have a longer history of addressing technical and theoretical topics; are based more frequently on computational linguistic studies of multiple languages; and address diverse topics. Chinese-language DH articles show a less diverse range of topics and place more emphasis on tools, libraries, and (more recently) the development of teaching. The methodology and results will be examined and presented more closely in the final paper. |
The conceptual foundations of the idea of government in the modern British eighteenth century: A distributional concept analysis
University of CambridgeIn this talk we introduce some of the techniques and methodology developed by the Cambridge Concept Lab for establishing the outlines or shapes of conceptual forms, what we call their ‘architecture’. These constructs are the product of a set of techniques applied to a digitized corpus – in this case Eighteenth Century Collections Online – which use computational and statistical means for establishing data driven descriptions of lexical behaviour which, we contend, allow us to inspect not only the linguistic but also the conceptual domain. Our project is not simply targeted at the ways in which the meanings of words in a natural language evolve over time. We are more interested in how these patterns of lexical co-association give us a window onto the underlying conceptual articulations which support the procedures and processes by which we make sense of the world. We present lexical co-association metrics derived from co-occurrences of words at different distances, varying from within the phrase level, to syntactic relations, to co-occurrences at discontinuous windows of up to 100 words. We use the connections defined by these measures to construct a network of terms, and examine this network for evidence of tightly bound sections forming cliques and or communities. We apply these methods and interactive visualisations of this distributional semantic evidence to track a bundle of terms that are important to the understanding of government in the eighteenth century, identifying a core comprised of the terms 'monarchy', 'aristocracy' and 'democracy' that has very deep foundations in our thinking polities and government within the Anglophone tradition from the Enlightenment on. |
A Question of Style: corpus building and stylistic analysis of the Edinburgh Review and Quarterly Review, 1814-1820
Open UniversityWe present our project, A Question of Style: individual voices and corporate identity in the Edinburgh Review, 1814-1820, funded by a Research Society for Victorian Periodicals Field Development Grant, which ran from January 2017 to 2017. We wanted to assess the assumption that early nineteenth-century periodicals succeeded in creating, through a “transauthorial discourse”, a unified corporate voice that hid individual authors behind an impersonal public text (Klancher 1987). Two years after our first presentation at DHC 2016, we will reflect on the progress of the project. We created a sample corpus of just over 787,000 words comprising 569,740 words from the Edinburgh Review and 217,801 words from its competitor, the Quarterly Review, drawn from 85 articles. To assist our OCR correction, metadata creation and textual markup, we intended developing a suite of Python scripts based on our previous work; but the demands of preparing a corpus for stylistic analysis took this work in another direction, which we will describe. We will evaluate our methods for measuring empirically select textual features, especially stylometry and corpus stylistics. We will debate whether our corpus shows traces of a “house style” for the Edinburgh and the Quarterly and whether the genre of the books being reviewed have an impact on stylistic analysis. We will discuss the effect of quoted texts on stylistic analysis and on the OCR correction process. Finally, we will qualitatively describe the results of this stylistic analysis and evaluate them within the context of both literary scholarship on nineteenth-century periodicals and computational linguistics scholarship, using our literary and historical interpretation to generate critical knowledge out of our measurements. Which aspects of authorship and style do computational methods allow us to perceive more clearly? Which do they at the same time obscure? |