Dewdrop
Funded by Jisc. Developed by HRI Digital at the University of Sheffield
Version 1.0 Available
Download version 1.0 (14th August 2017): dewdrop-v1.0.zip
The zip file is approximately 786 MB in size. It contains the Dewdrop program and all user documentation.
Read the Quick Start Guide
You can view the full documentation for Dewdrop here
Download the source code, modify it, improve it, mix it, and share it, with a GNU General Public License v3.0.
Help! You can contact the DHI at dhi@sheffield.ac.uk
Introducing Dewdrop and Discovery-Friendly Records
- Dewdrop is a software program designed to create discovery-friendly records of your website. It is a web crawler combined with a text analyser.
- Dewdrop is designed to make your website content more easily accessible to search engines and third-party content aggregators by creating versions of your content (discovery-friendly records) that these services understand. You can also use Dewdrop to acquire content from third-party websites for your own data mining and other research purposes.
- Dewdrop is particularly suitable for poorly designed websites that cannot be easily discovered or indexed by search engines and third-party content aggregators.
- Dewdrop's discovery-friendly records do not make your existing website content invalid. The records act as signposts, directing search engines and content aggregators to your website.
- Dewdrop requires minimal technical know-how.
- Dewdrop will crawl your website (HTML pages, PDF documents, Word documents and database content), analyse the textual content of your website and then create new, discovery-friendly records.
- Discovery-friendly records are a version of your website content that is presented in HTML RDFa, RDF or JSON-LD formats, depending on your preference. We recommend HTML RDFa for beginners.
- When Dewdrop has finished you can ask your server administrator to save these records to the root directory of your website. They will site alongside your existing website content.
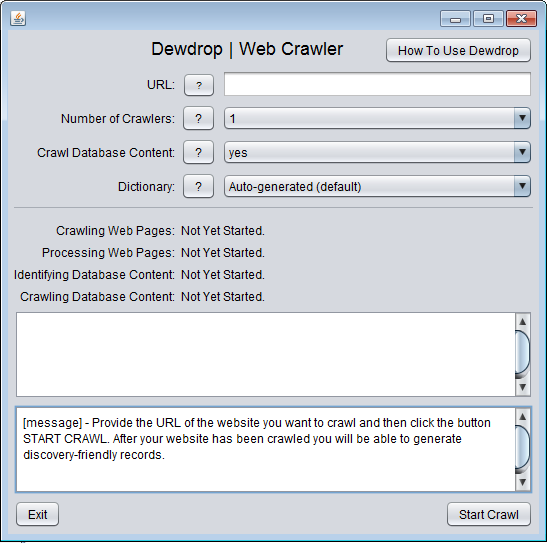
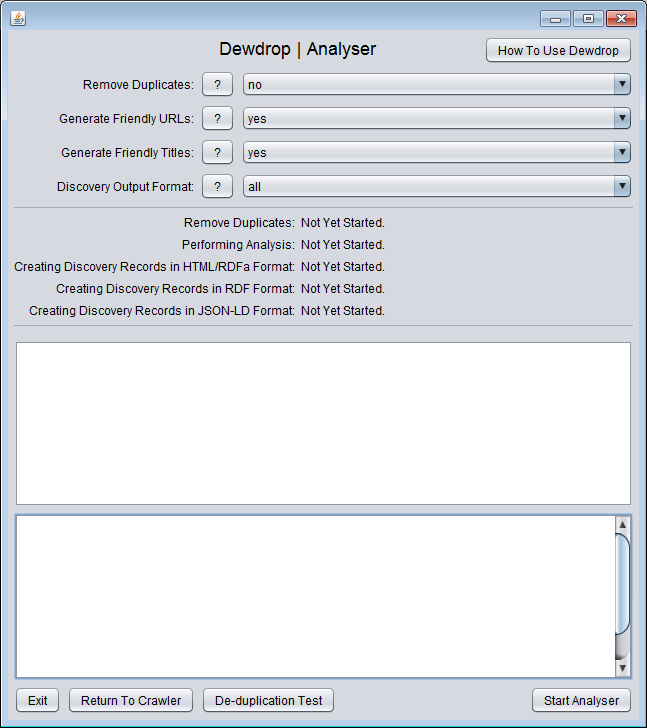
- There are only two screens for the user interface. You can see what the screens look like here: Screen#1: Crawler and here: Screen #2: Analyser
- Read the Quick Start Guide.
Minimum System Requirements
- 8GB RAM, i5 processor.
- A hard drive of at least 397MB (Dewdrop's program size). However, your hard drive also needs enough space to accommodate the data being retrieved and processed by Dewdrop; which is dependent on the size of the website being crawled. At least 1GB is recommended.
- Dewdrop requires Java to be installed on your computer. You can download the latest version from here: https://java.com/en/download.
- Dewdrop will work on any operating system that has Java installed.
- For information, the following system features will impact on the overall speed of Dewdrop:
- The read/write speed of your hard drive.
- The size and read/write speed of your RAM (memory).
- The speed of your internet connection.
- The speed of your computer's processor and the number of cores.
You can view the full documentation for Dewdrop here
{kind=link}
{kind=link}