The Library Catalogue as Dataset: Exploring Data Science Approaches to Analyse Collections at Scale
- Lucy Havens University of Edinburgh
- Paul Gooding University of Glasgow
- Kirsty Lingstadt University of Edinburgh
- Alex Forrest University of Edinburgh
- Alasdair MacDonald University of Edinburgh
- Melissa Terras University of Edinburgh
Keywords: Library Science, Data Visualisation, Digital Library
Abstract:
How can we use data science to understand academic library holdings at scale? Can we use library catalogues to understand the historical growth of collections, acquisition practices, subject level specialisms, biases, or how a collection reflects the library’s stated acquisition strategy? We present the Edinburgh University Library Metadata Visualizations Project, which used MARC (Machine Readable Cataloging) metadata, the international standard for dissemination and searching of bibliographic data (Schudel 2006, Library of Congress 2019), as a rich source to understand holdings.
Library catalogue data is an example of a Humanities dataset that is complex, challenging, heterogeneous, fragmentary, multilingual, and ambiguous (Lazer et al 2009, Kitchin 2014, Guiliano and Ridge 2016, Underwood 2018, Alex et al 2019). Most data processing of MARC focusses on improvement of the records, although previous work has used MARC to understand biases (Diao and Cao 2016, Lavoie 2018), and for library analytics (Harper 2016).
The University Library’s MARC data for its 1,297,311 print books was downloaded from OCLC (the “physical collection”: avoiding complexities of syndication to electronic sources). Data was translated to CSV and cleaned using Python and Pandas scripts. Visualisations were created from samples of the data using Python, Microsoft Excel and Adobe InDesign. Our code is available on GitHub.
1 https://marcedit.reeset.net
2 https://www.oclc.org/en/home.html
3 https://pandas.pydata.org
4 https://github.com/lib-viz/summer
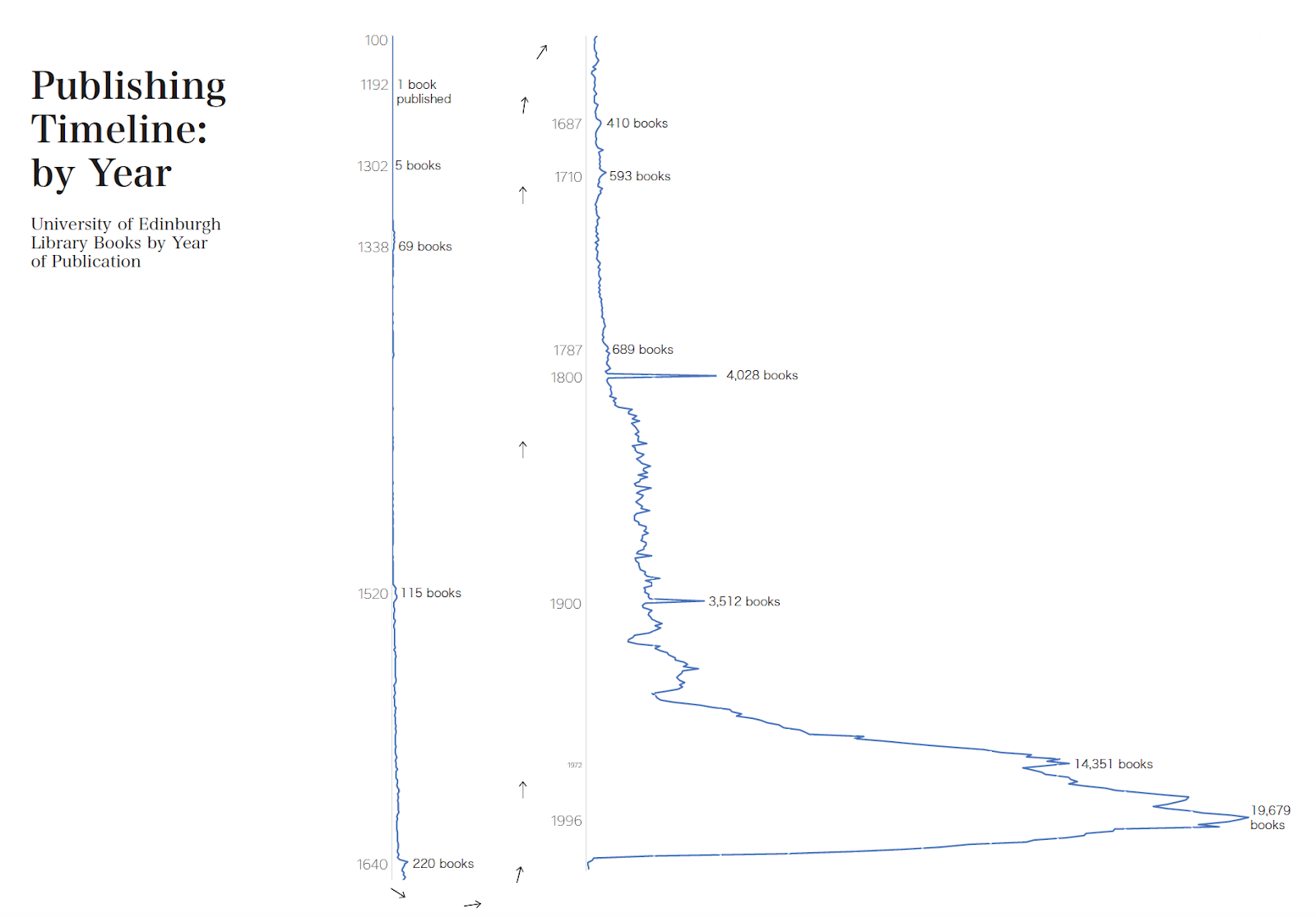
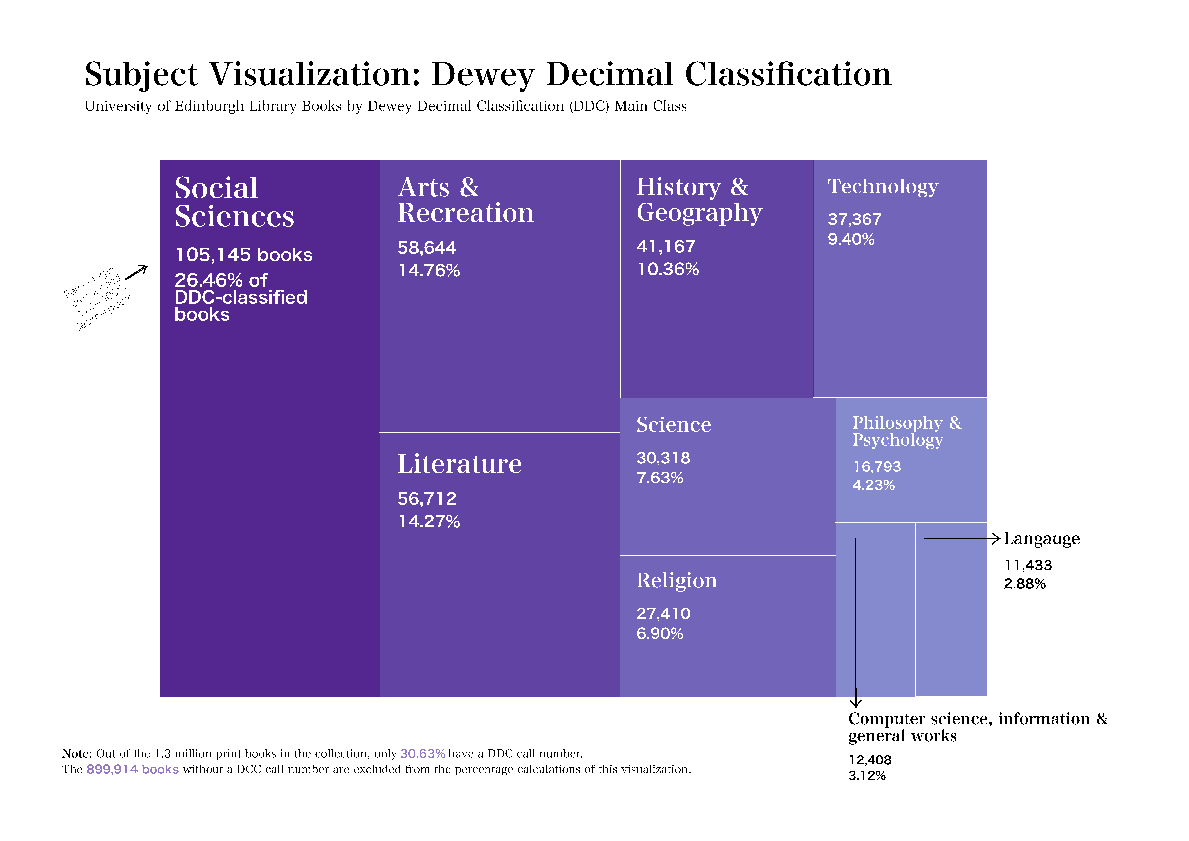
We show that MARC is suitable for visualization, and provide insights into collections’ practices and strengths. However, lack of standardization in data entries requires extensive data cleaning, for example books’ publications dates, or geographic location (71.9% books have no known place of publication without further analysis). Subject classification data entries did not require standardization. Future work could build on this project through further data cleaning, visualization development, methods for detecting accuracy of this approach, and comparison with other datasets. We demonstrate that library catalogues, as “collections as data” (Padilla et al 2019) hold a rich, but untapped, resource for understanding information environments.
Bibliography
Alex, B., Alexander, A., Beavan, D., Goudarouli, E., Impett, L., McGillivray, B., McGregor, N., & Ridge, M. (2019). Data Science & Digital Humanities: New collaborations, new opportunities and new complexities. Digital Humanities 2019, Utrecht, The Netherlands. https://staticweb.hum.uu.nl/dh2019/dh2019.adho.org/panels/index.html
Diao, J. & Cao, H., 2016. Chronology in Cataloging Chinese Archaeological Reports: An Investigation of Cultural Bias in the Library of Congress Classification. Cataloging & Classification Quarterly 54:4, 244-262.
Harper, C. A., 2016. Metadata Analytics, Visualization and Optimization: Experiments in statistical analysis of the Digital Public Library of America (DPLA). Code4Lib Journal 33.
Guiliano, J., & Ridge, M. (2016). The Future of Digital Methods for Complex Datasets: An Introduction. International Journal of Humanities and Arts Computing, 10(1), 1–7. https://doi.org/10.3366/ijhac.2016.0155
Kitchin, R. 2014. Big Data, new epistemologies and paradigm shifts. Big data & Society, 1(1).
Lavoi, B. 2018. How information about library collections represents a treasure trove for research in the humanities and social sciences. LSE Impact of Social Sciences Blog. September 19th, 2018. https://blogs.lse.ac.uk/impactofsocialsciences/2018/09/19/how-information-about-library-collections-represents-a-treasure-trove-for-research-in-the-humanities-and-social-sciences/
Lazer, D., Pentland, A., Adamic, L., Aral, S., Barabási, A.L., Brewer, D., Christakis, N., Contractor, N., Fowler, J., Gutmann, M. and Jebara, T., 2009. Computational social science. Science, 323(5915), pp.721-723.
Library of Congress. 2019. MARC Standards. https://www.loc.gov/marc/.
Padilla, T., Allen, A., Frost, H., Potvin, S., Russey Roke, E., Varner, S. 2019. “Final Report: Always Already Computational: Collections as Data”. https://doi.org/10.5281/zenodo.3152935/.
Schudel, M. 2006. “Henriette Avram, 'Mother of MARC,' Dies”. https://www.loc.gov/loc/lcib/0605/avram.html
Underwood, T. 2018. “Why an Age of Machine Learning Needs the Humanities.” Public Books (blog). December 5, 2018. https://www.publicbooks.org/why-an-age-of-machine-learning-needs-the-humanities/
-
Session 10
Friday 11:30 - 13:00
High Tor 2
Papers:
- Digital Initiatives in Online Service Delivery: Case Study of London Art Museums During the COVID-19 Pandemic Lockdown
- Exploring Early British Photography and the Impact of the 1862 Fine Arts Copyright Act through the Application of Digital Methods of Analysis to Archival Catalogue Data
- The Library Catalogue as Dataset: Exploring Data Science Approaches to Analyse Collections at Scale