Session 10Friday 11:30 - 13:00High Tor 2Chair: Kate Simpson |
|---|
Digital Initiatives in Online Service Delivery: Case Study of London Art Museums During the COVID-19 Pandemic Lockdown
University College LondonKeywords: Digital museum; Online service; User engagement Abstract: The outbreak of COVID-19 has had an unprecedented impact on the GLAM (galleries, libraries, archives, and museums) sector around the world (ICOM, 2020; UNESCO, 2020; ICOM, 2021). Institutions have been experimenting with new ways to engage with the public remotely. As museums and galleries continue to navigate the widespread impact of the pandemic lockdown, as well as envision the future of the cultural industry, it is clear that digital considerations remain crucial (Agostino et al., 2021; Raghavan et al., 2021). Within this context, this paper investigates the digital initiatives that museums have developed on Facebook for online service delivery in response to the COVID-19 pandemic lockdown. Empirically, with basic statistical analysis and content analysis as the main research methods, three London-based art museums were chosen for this study, which are National Gallery, Tate, and the Victoria and Albert Museum (V&A). This paper reflects on the challenges faced by museum professionals in supporting their audiences offsite. Additionally, by analysing and comparing how these three institutions used Facebook and the user engagement behaviours generated, it provides insights into how museums could utilise their resources more efficiently when developing digital initiatives, not just in coping with public emergencies. Our findings demonstrate that museums need not only to be responsive, but also to develop for empathetic, supportive, and consistent strategies in online service delivery. Reference: Agostino, D., Arnaboldi, M. and Lema, M.D., 2021. New development: COVID-19 as an accelerator of digital transformation in public service delivery. Public Money & Management, 41(1), pp.69-72. International Council of Museums (ICOM)., 2020. Museums, museum professionals and Covid-19 https://icom.museum/wp-content/uploads/2020/05/Report-Museums-and-COVID-19.pdf International Council of Museums (ICOM)., 2021. Museums, museum professionals and Covid-19: third survey https://icom.museum/wp-content/uploads/2021/07/Museums-and-Covid-19_third-ICOM-report.pdf Raghavan, A., Demircioglu, M.A. and Orazgaliyev, S., 2021. COVID-19 and the new normal of organizations and employees: an overview. Sustainability, 13(21), p.11942. United Nations Educational, Scientific and Cultural Organization (UNESCO)., 2020. Museums around the world in the face of COVID-19. https://unesdoc.unesco.org/ark:/48223/pf000037353 |
Exploring Early British Photography and the Impact of the 1862 Fine Arts Copyright Act through the Application of Digital Methods of Analysis to Archival Catalogue Data
The National Archives, UKKeywords: photography, data analysis, archives Abstract: In 1862 the Fine Arts Copyright Act was passed into law in the United Kingdom. Previous copyright legislation had protected books, engravings and certain works of art, but this Act for the first time conferred copyright protection on three specific categories: paintings, drawings, and photographs. The medium of photography was in in its infancy in the 1860s so its inclusion in the Act was controversial and ground-breaking. Between 1862 and 1912, photographers sent copies of their work to the Stationers’ Company to be registered for copyright protection and these records are now held at The National Archives, offering an incredible insight into the early days of photography. This paper seeks to examine the state of the British photographic industry and its initial response to the 1862 Act, through digital analysis of the catalogue data for this collection of copyright records (made possible through volunteer-led cataloguing of the collection). While this collection has been catalogued by volunteers, making digital analysis possible, the catalogue data is limited to simple text-based fields presenting obstacles for this analysis. Using Python and libraries including Pandas (for data analysis) and spaCy (for natural language processing) to clean, analyse and visualise the data, I intend to offer statistical insights on the quantities and types of photographs that were registered and the people who registered them. This will make it possible to observe artistic and commercial trends and professional connections between photographers and other actors in the photographic industry at the time. Through this exploration, this paper also seeks to demonstrate the research potential of using methods of digital analysis to extract new insights from existing archival catalogue data, particularly flawed data which has previously been considered less suitable for digital analysis. |
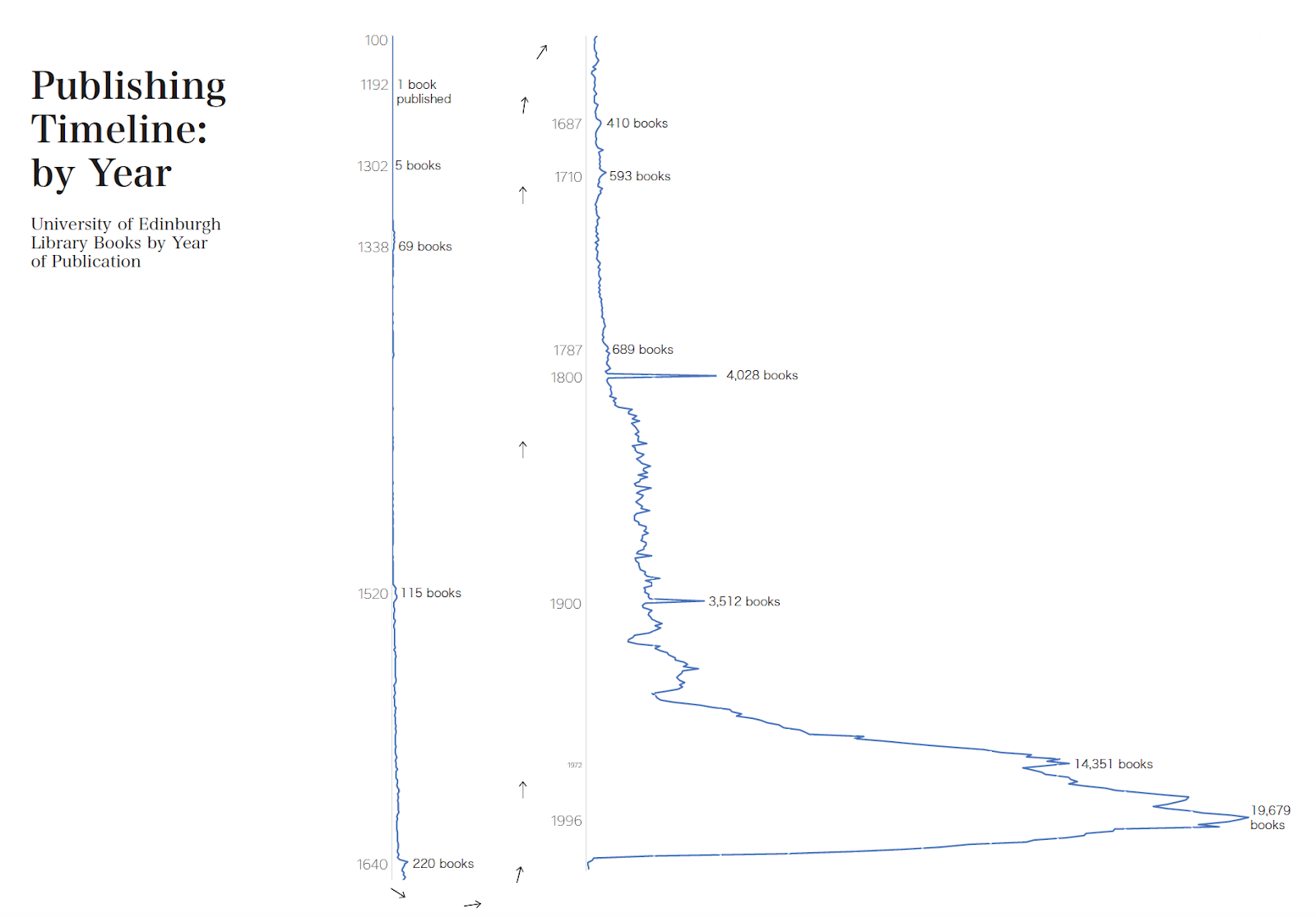
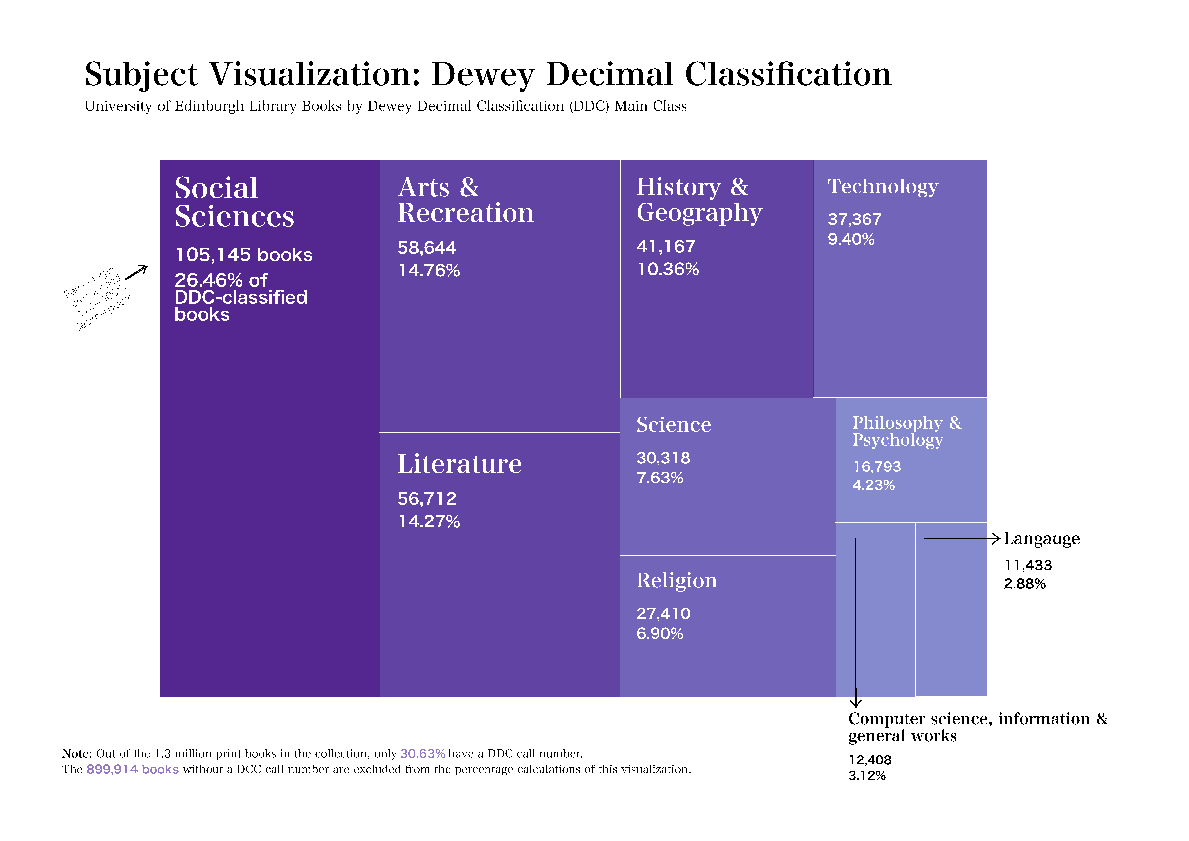
The Library Catalogue as Dataset: Exploring Data Science Approaches to Analyse Collections at Scale
University of EdinburghKeywords: Library Science, Data Visualisation, Digital Library Abstract: How can we use data science to understand academic library holdings at scale? Can we use library catalogues to understand the historical growth of collections, acquisition practices, subject level specialisms, biases, or how a collection reflects the library’s stated acquisition strategy? We present the Edinburgh University Library Metadata Visualizations Project, which used MARC (Machine Readable Cataloging) metadata, the international standard for dissemination and searching of bibliographic data (Schudel 2006, Library of Congress 2019), as a rich source to understand holdings. Library catalogue data is an example of a Humanities dataset that is complex, challenging, heterogeneous, fragmentary, multilingual, and ambiguous (Lazer et al 2009, Kitchin 2014, Guiliano and Ridge 2016, Underwood 2018, Alex et al 2019). Most data processing of MARC focusses on improvement of the records, although previous work has used MARC to understand biases (Diao and Cao 2016, Lavoie 2018), and for library analytics (Harper 2016). The University Library’s MARC data for its 1,297,311 print books was downloaded from OCLC (the “physical collection”: avoiding complexities of syndication to electronic sources). Data was translated to CSV and cleaned using Python and Pandas scripts. Visualisations were created from samples of the data using Python, Microsoft Excel and Adobe InDesign. Our code is available on GitHub. 1 https://marcedit.reeset.net 2 https://www.oclc.org/en/home.html 3 https://pandas.pydata.org 4 https://github.com/lib-viz/summer
We show that MARC is suitable for visualization, and provide insights into collections’ practices and strengths. However, lack of standardization in data entries requires extensive data cleaning, for example books’ publications dates, or geographic location (71.9% books have no known place of publication without further analysis). Subject classification data entries did not require standardization. Future work could build on this project through further data cleaning, visualization development, methods for detecting accuracy of this approach, and comparison with other datasets. We demonstrate that library catalogues, as “collections as data” (Padilla et al 2019) hold a rich, but untapped, resource for understanding information environments.
Bibliography Alex, B., Alexander, A., Beavan, D., Goudarouli, E., Impett, L., McGillivray, B., McGregor, N., & Ridge, M. (2019). Data Science & Digital Humanities: New collaborations, new opportunities and new complexities. Digital Humanities 2019, Utrecht, The Netherlands. https://staticweb.hum.uu.nl/dh2019/dh2019.adho.org/panels/index.html Diao, J. & Cao, H., 2016. Chronology in Cataloging Chinese Archaeological Reports: An Investigation of Cultural Bias in the Library of Congress Classification. Cataloging & Classification Quarterly 54:4, 244-262. Harper, C. A., 2016. Metadata Analytics, Visualization and Optimization: Experiments in statistical analysis of the Digital Public Library of America (DPLA). Code4Lib Journal 33. Guiliano, J., & Ridge, M. (2016). The Future of Digital Methods for Complex Datasets: An Introduction. International Journal of Humanities and Arts Computing, 10(1), 1–7. https://doi.org/10.3366/ijhac.2016.0155 Kitchin, R. 2014. Big Data, new epistemologies and paradigm shifts. Big data & Society, 1(1). Lavoi, B. 2018. How information about library collections represents a treasure trove for research in the humanities and social sciences. LSE Impact of Social Sciences Blog. September 19th, 2018. https://blogs.lse.ac.uk/impactofsocialsciences/2018/09/19/how-information-about-library-collections-represents-a-treasure-trove-for-research-in-the-humanities-and-social-sciences/ Lazer, D., Pentland, A., Adamic, L., Aral, S., Barabási, A.L., Brewer, D., Christakis, N., Contractor, N., Fowler, J., Gutmann, M. and Jebara, T., 2009. Computational social science. Science, 323(5915), pp.721-723. Library of Congress. 2019. MARC Standards. https://www.loc.gov/marc/. Padilla, T., Allen, A., Frost, H., Potvin, S., Russey Roke, E., Varner, S. 2019. “Final Report: Always Already Computational: Collections as Data”. https://doi.org/10.5281/zenodo.3152935/. Schudel, M. 2006. “Henriette Avram, 'Mother of MARC,' Dies”. https://www.loc.gov/loc/lcib/0605/avram.html Underwood, T. 2018. “Why an Age of Machine Learning Needs the Humanities.” Public Books (blog). December 5, 2018. https://www.publicbooks.org/why-an-age-of-machine-learning-needs-the-humanities/
|